
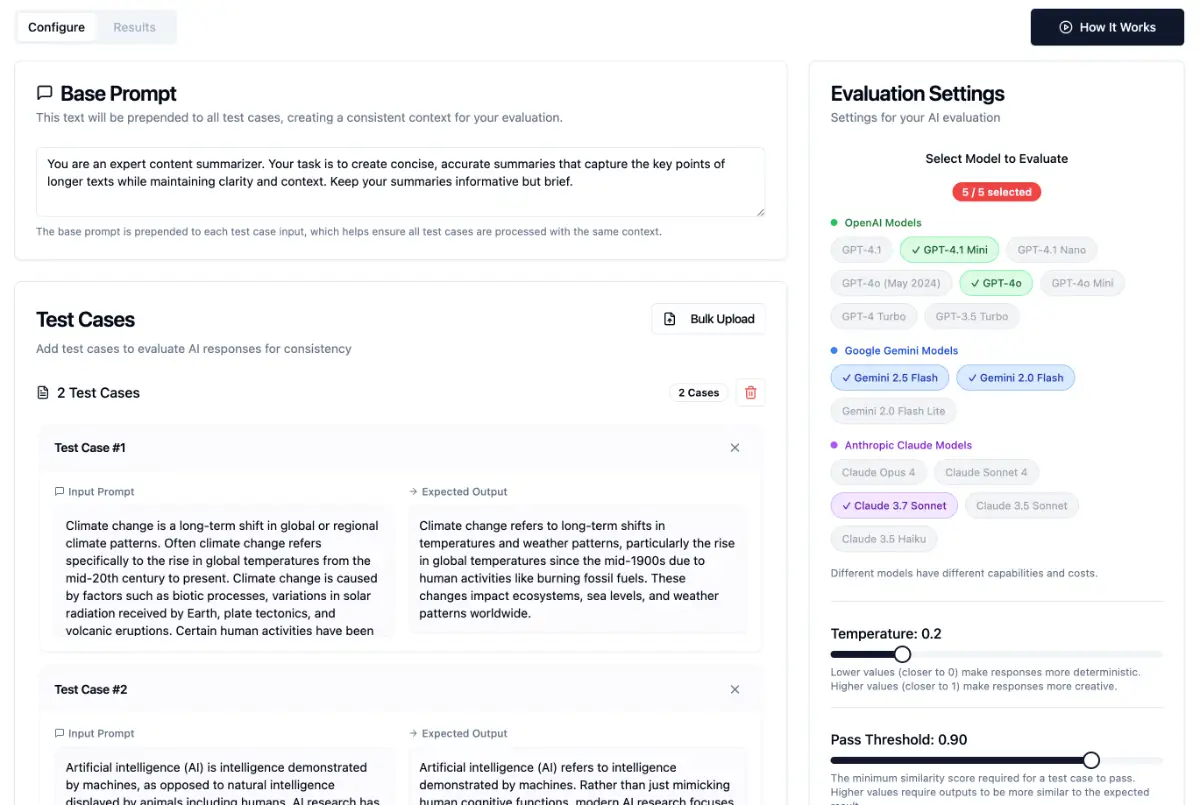
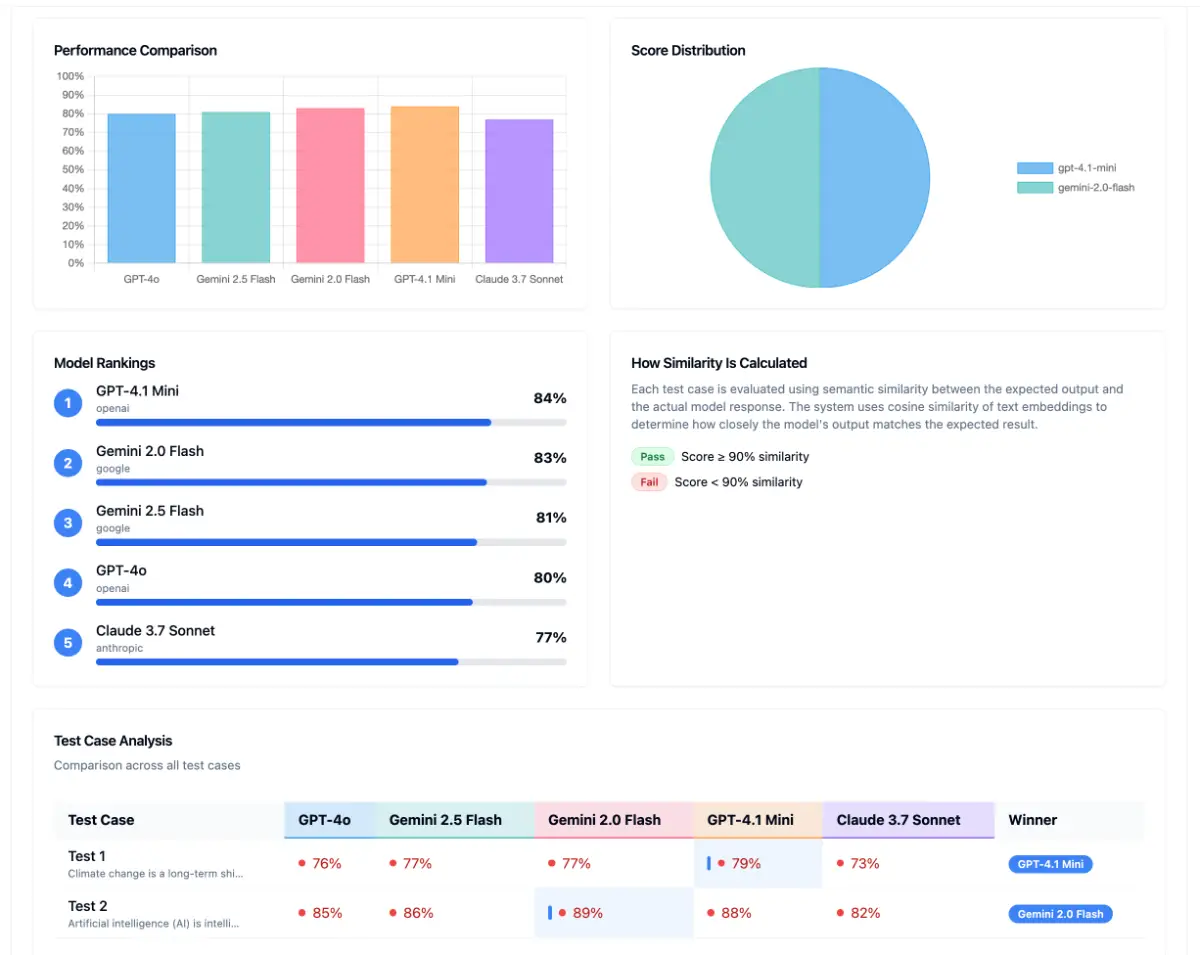
LLM models are changing fast -> Gemini 1.0 and GPT-4 gets quietly updated, models get deprecated, and the same prompt suddenly gives different results.
PromptPerf helps you stay ahead.
It lets you test a single prompt against multiple OpenAI models and compares the results to your expected output using semantic similarity scoring.
Perfect for:
Prompt engineers, AI devs, and product teams
Quickly validating prompt reliability
Spotting regressions as models evolve
At launch:
✅ 3 AI Providers 9+ models
✅ CSV and JSON export
✅ Built-in scoring, no manual tracking
We're just getting started: more models, batch runs, and evaluations are on the way. Feedback shapes the roadmap.
🔗 Try https://PromptPerf.dev →
Offering 75% off lifetime plan.
Built + launched solo. Feedback welcome 🙏

